
Toward unlocking the potential of generative models in immersive 4D experiences, we introduce Virtual Pet, a novel pipeline to model realistic and diverse motions for target animal species within a 3D environment. To circumvent the limited availability of 3D motion data aligned with environmental geometry, we leverage monocular internet videos and extract deformable NeRF representations for the foreground and static NeRF representations for the background. For this, we develop a reconstruction strategy, encompassing species-level shared template learning and per-video fine-tuning. Utilizing the reconstructed data, we then train a conditional 3D motion model to learn the trajectory and articulation of foreground animals in the context of 3D backgrounds. We showcase the efficacy of our pipeline with comprehensive qualitative and quantitative evaluations. We also demonstrate versatility across unseen cats and indoor environments, producing temporally coherent 4D outputs for enriched virtual experiences.

Diverse Environment-aware Motion Generation. We show the diverse motion generations in different environments. (Top) We show 4D generation given different starting poses G0. (Bottom) We show diverse motion outputs given the same starting pose in the same scene. The proposed method can generate diverse motions in different environments.

Diverse Environment-aware Motion Generation. We show the diverse motion generations rendering in multi-view.

Diverse textures. We adopt Text2Tex and SceneTex to perform diverse texturing to both foreground objects and background scenes.
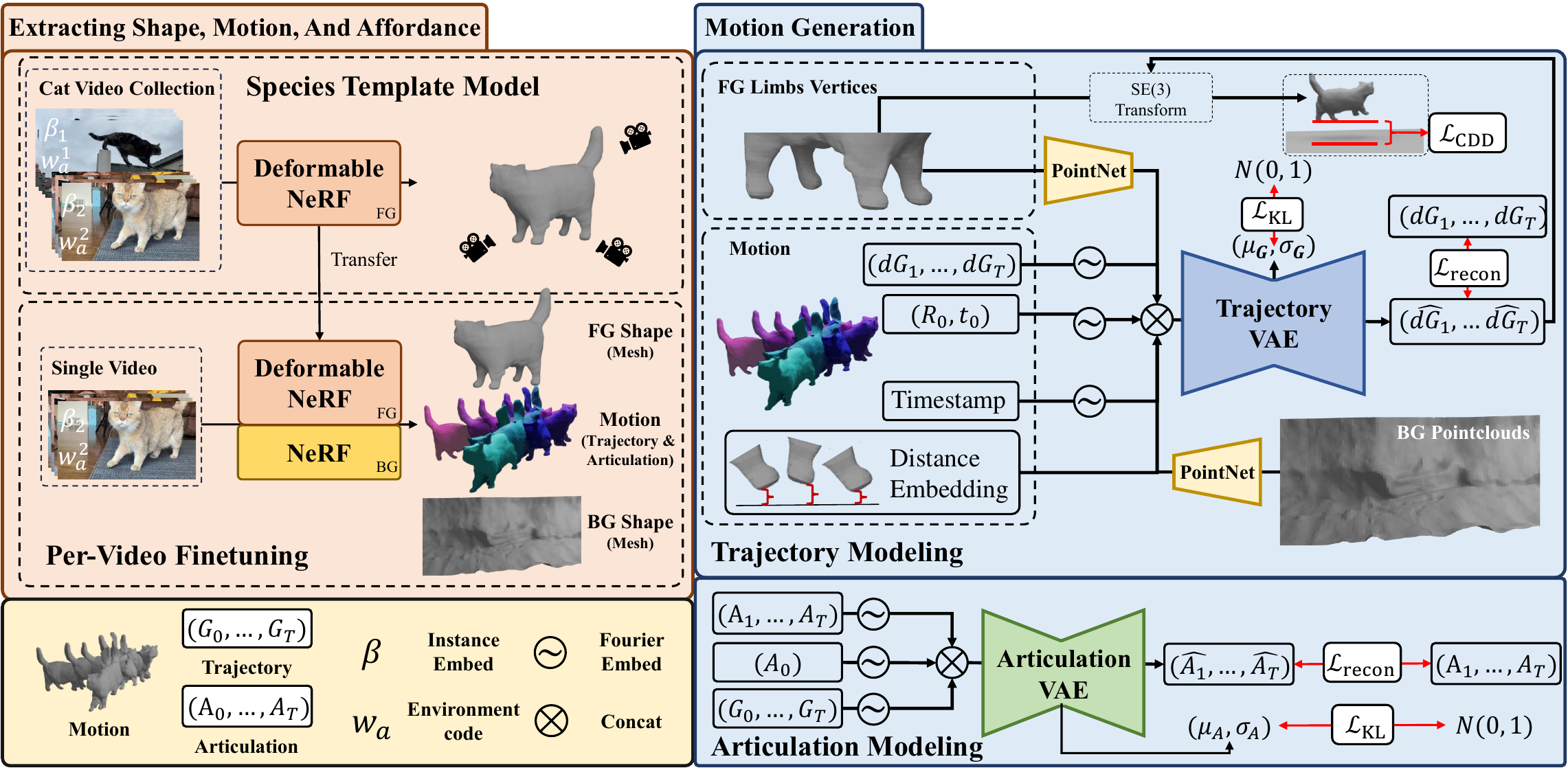
The proposed framework of Virtual Pets.
(Left) To extract 3D shapes and motions from monocular videos: we first learn a Species
Articulated Template Model with an articulated NeRF using a collection of cat videos. We then perform Per-Video Fine-tuning.
For each video, we further reconstruct the background with a static NeRF. The articulated NeRF trained in species-level stage is loaded
and fine-tuned in this stage to make sure the motions, which are Trajectory and Articulation, respect the reconstructed background shape.
(Right) After that, we train an environment-aware 3D motion generator with a Trajectory VAE and an Articulation VAE. It generates 3D motions
based on vertices of the foreground limbs, distance from foreground to background, and pointclouds sampled from the background
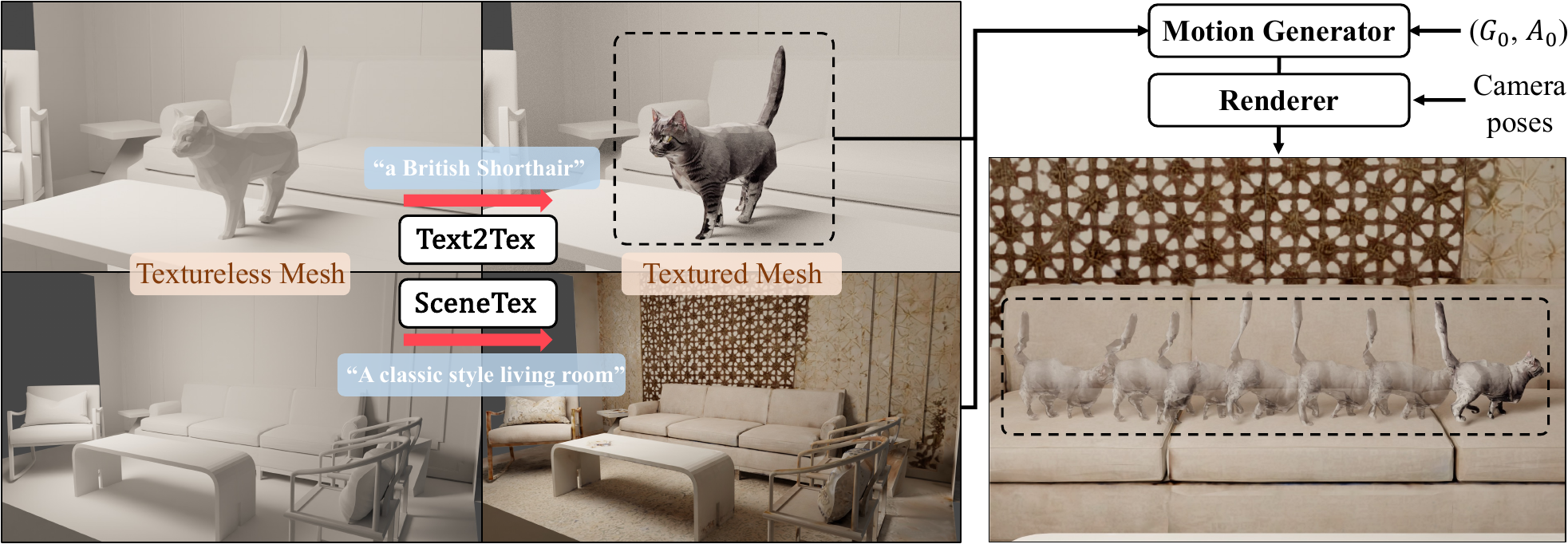
Inference: Texturing and Rendering. At the inference time, given textureless foreground and background meshes, we first adopt Text2Tex and SceneTex to texture the meshes. Meanwhile, we generate the motion sequence using the trained trajectory VAE and articulation VAE. We then obtain the final predicted foreground mesh after deformation and transformation. Finally, the 3D motion sequences and the 3D scene are rendered to videos given camera poses.
@article{cheng2023VirtualPets,
title = {{V}irtual {P}ets: Animatable Animal Generation in 3D Scenes},
author={Cheng, Yen-Chi and Lin, Chieh Hubert and Wang, Chaoyang and Kant, Yash and Tulyakov, Sergey and Schwing, Alexander G and Gui, Liangyan and Lee, Hsin-Ying},
journal = {arXiv preprint arXiv:2312.14154},
year={2023},
}