|
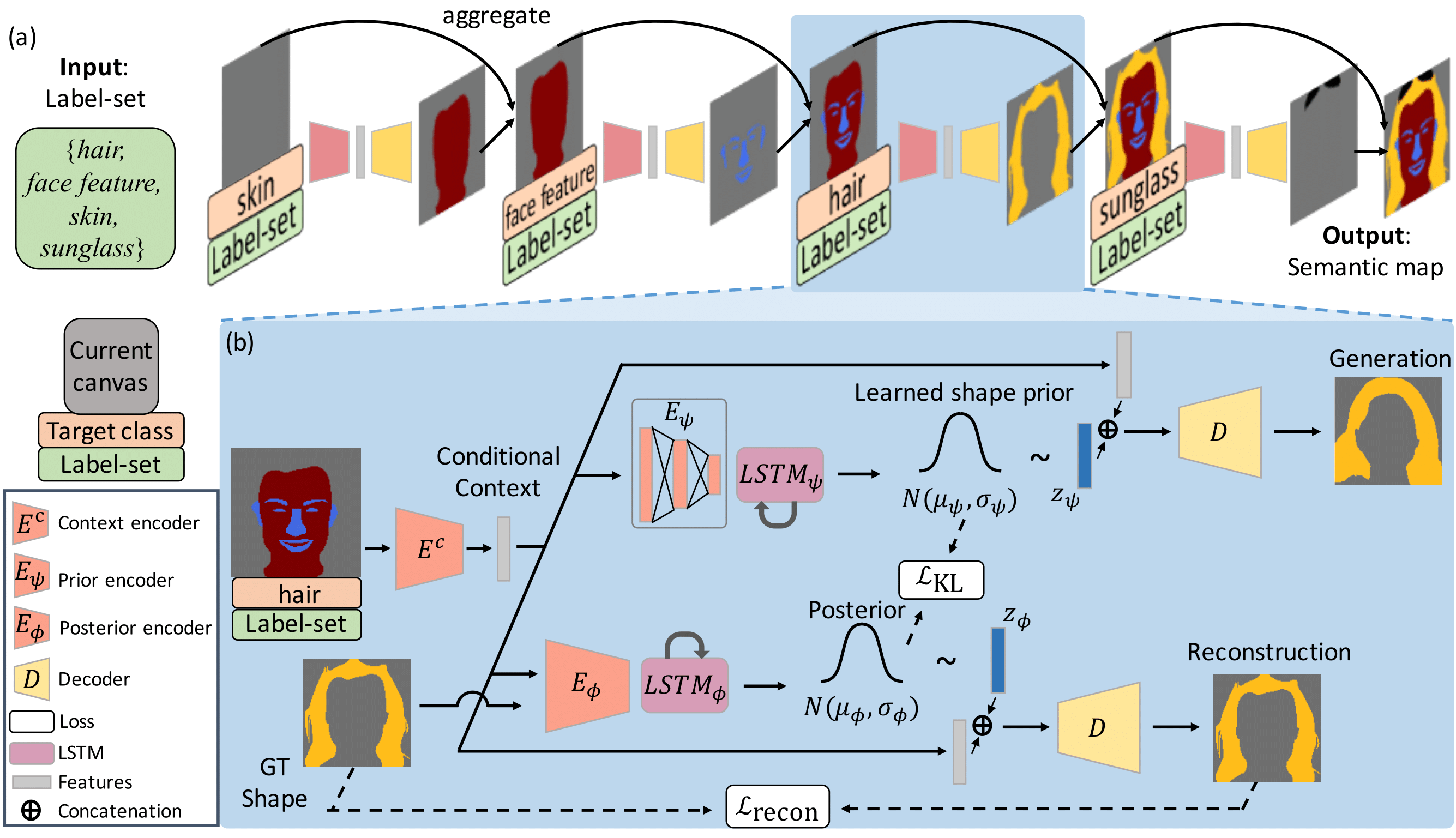
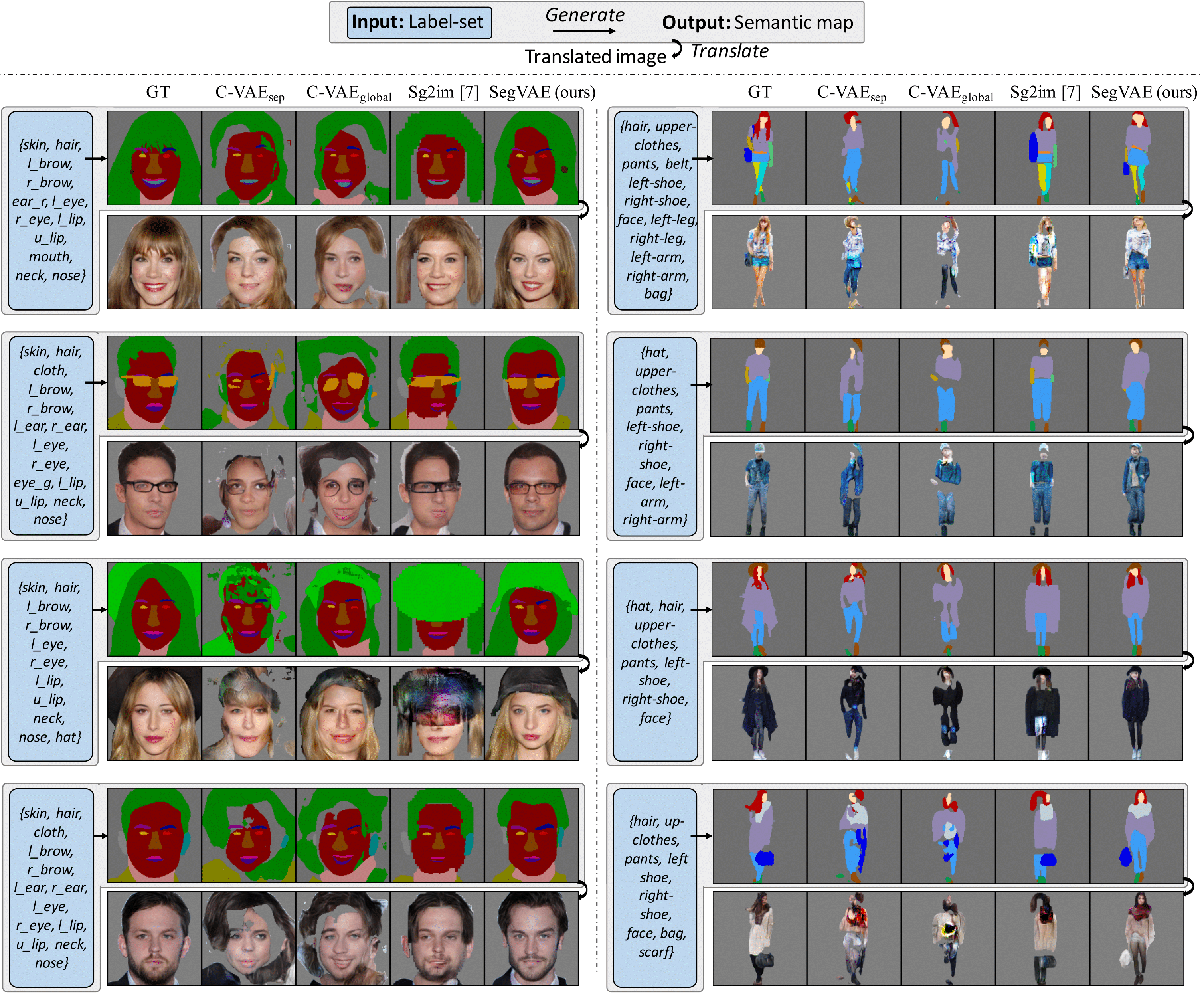
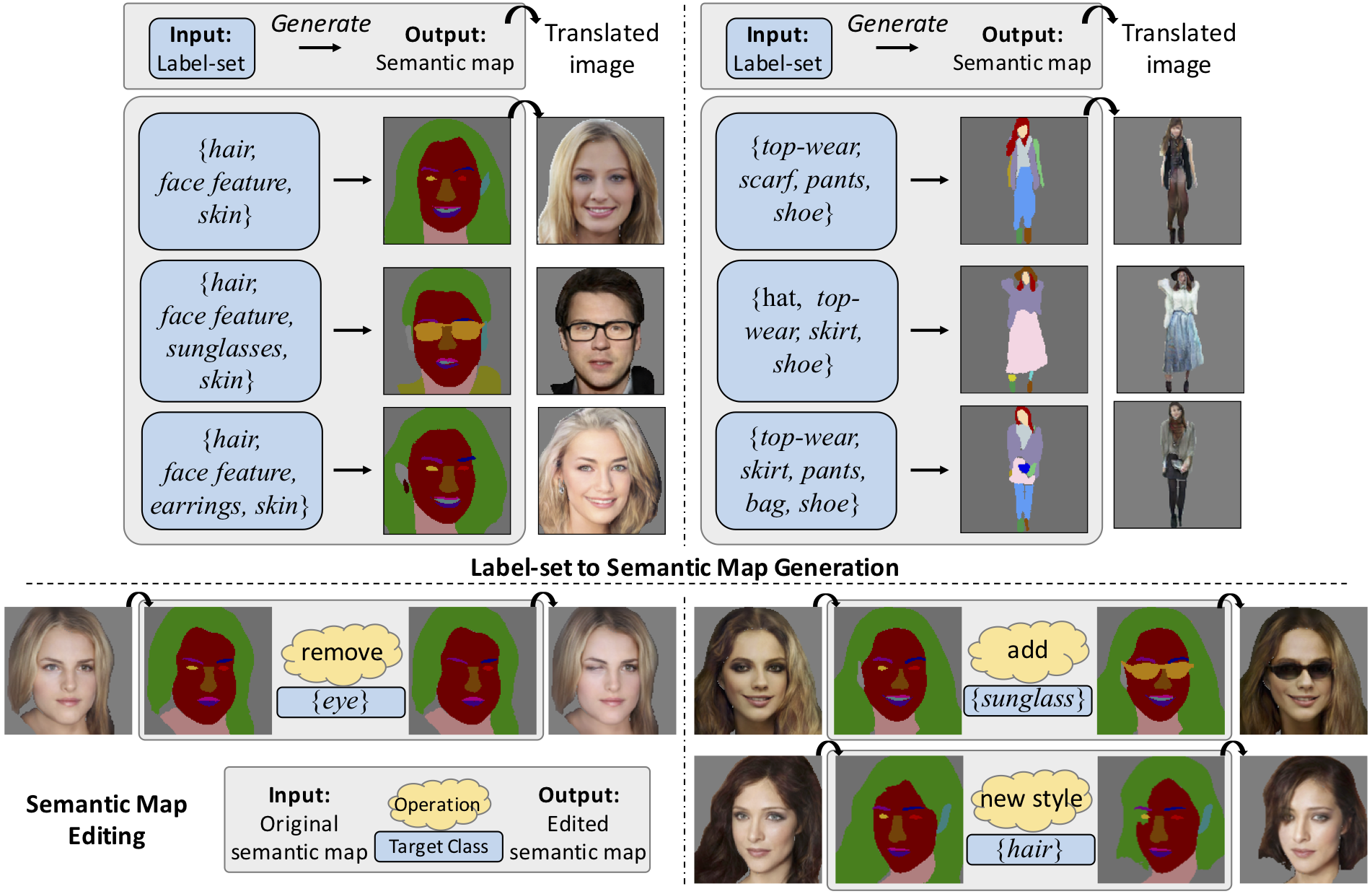
| Label-set to Semantic map generation. (Top) Given a label-set, our model can generate diverse and realistic semantic maps. Translated RGB images are shown to better visualize the quality of the generated semantic maps. (Bottom) The proposed model enables several real-world flexible image editing. |